

【同志社大学】データサイエンスで紐解く古典和歌の世界
同志社大学文化情報学部文化情報学科
日本文学研究室

専門:日本古典文学/人文社会情報学
AI・データサイエンス系大学・学部の研究室では、どのような研究が行われている?データサイエンスのスキルはあらゆる学問分野で応用可能であり、文学研究も例外ではない。かつての風景の美しさや人々の想いを言葉にすることで受け継いできた和歌には、膨大なデータの蓄積があり、むしろデータサイエンスと親和性が高いと言える。主に古典和歌のデータを対象に研究を行う同志社大学文化情報学部の福田智子教授に話を聞いた。
情報系学部における文学研究とは?
文理融合の教育を展開する同志社大学文化情報学部のコンセプトは、「文化」を「データ」として読み解き、人間を理解すること。情報学や統計学などの理系分野はもちろん、哲学、音楽、映像学、考古学、言語学、社会学など、文系分野も含めた幅広い領域でデータサイエンスが実践されている。日本古典文学を専門に扱う福田智子教授の日本文学研究室もそのひとつ。福田教授の研究室では、主に古典和歌を対象にデータサイエンスを駆使した研究が行われている。
「みなさんご存知の通り、和歌とは『五・七・五・七・七』で四季の美しさや人間の心模様などを表現する芸術です。明治以降の近代短歌の表現は、概ねルールに縛られることなく自由なのですが、古典和歌の世界には、掛詞、縁語、枕詞など、表現を豊かにするためのさまざまな決まりごとがあります。私はこれを『美の型』と呼んでいます」
「学ぶ」は「まねぶ」(真似をすること)だと福田教授は語る。その時代のカラーを少しずつ取り入れながらも、これまでの芸術の型を守り、本質を次世代へと伝承していくことが和歌において重要な要素だという。そのため、過去のデータの蓄積を活用するデータサイエンスは、和歌研究において親和性のある領域になる。継承されてきた和歌データを活用することで、新たな文学研究の可能性も見えてくるかもしれない。日本文学研究室が情報系学部のなかに設置されていることの魅力がここにある。
データマイニングで未発見の「本歌取り」を探してみる
「美の型」のひとつとして、「本歌取り」というものがある。これは、和歌を作る際、過去に詠まれた歌の語句や発想、趣向などを意識的に取り入れて、一首の歌の内容に奥行きと広がりをもたせる表現技巧のこと。ある和歌のなかに別の和歌の情感や風景を思い浮かべることによって、余情を高める効果が生まれる。例えば、藤原定家は、持統天皇の歌を本歌取りして、夏の到来を詠んだ。白い衣と卯の花のイメージを描きながら、夏になると白い衣を干すという天の香具山をも想起させ、重層的な広がりによる感動を届けたのである。
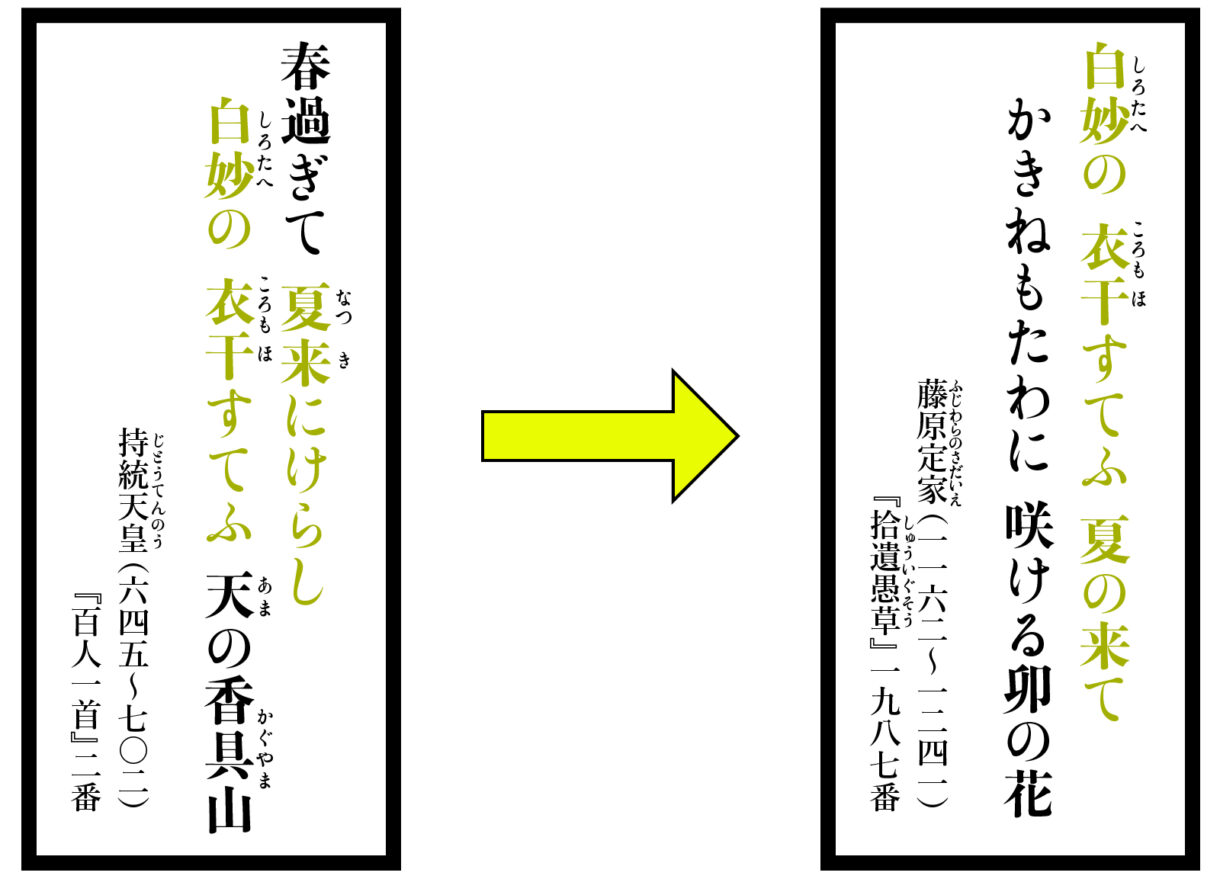
「古典和歌は、美の型を真似し真似されることで伝統を受け継いできました。そのため、和歌研究においても、同じ語句や用法が使われた歌を網羅的に集め、考察する手法がとられています。それでは似た歌を探すにはどうすればいいでしょうか。このときに便利なのが、『新編国歌大観』という約45万首が収録されたデータベースです。私が学生の頃は、書籍版しかなく、その句索引を使って似た歌を探していましたが、現在ではテキストがデジタル保存されていますので非常に便利です。コンピュータに複数の語句を入力して検索すれば、似た歌を見つけることができます。しかし、検索する際に入力する語句を思いつかない場合にはどうしましょう。そこで重要なのがデータマイニングという発想です」

「デジタル化された和歌の膨大なテキストに対してデータマイニングを用います。データマイニングとは、膨大なデータから法則性を見つけたり、有益な情報を取り出したりすること。これを和歌に応用して、似た和歌を抽出します」
和歌を対象にしたデータマイニングを行う上で福田教授が設定したルールが、以下の2つ。
①品詞分解などを行わず、和歌を単なる仮名文字列として捉えること
②文字列は一致していても語句の意味が異なる場合を想定し、ペナルティ値を付与すること
①は、これまでの手法では見つけられなかった本歌取りを発見するのが目的で、生物のゲノム解析(DNAの塩基配列の解読)からヒントを得たのだという。意味のある文としてではなく、あくまで単なる仮名文字の連鎖として捉えるのがポイントだ。②については、品詞分解をしていないことから生じる語の切れ端の一致に対処するためである。例えば、『古今和歌集』と『後撰和歌集』との間で、和歌を1首ずつ取り出してペアを作り、類似度を出すと下図のようになる。

最も単純には、5文字一致ならばその文字数分の5点とするところだが、同じ5文字一致でも、(c)のように一箇所にまとまっていると、ペナルティ値0.9を1回だけ引く。その一方、(b)のように二箇所に分かれていると、ペナルティ値0.9を2回引くことになり、それだけ類似度が下がることになる。
「計算機は、2つの和歌の集合の間で1首ずつ総当たりにペアを作り、この類似度を計算していきます。古今和歌集の1111首と後撰和歌集の1425首との間では、それこそ膨大な和歌のペアが出力されます。しかしながら、似た和歌のデータが出力されたら、それで研究成果になるわけではありません。類似度の高いペアから順に見ていくことで、どのペアに着目するか、また、それをどのような文学研究・和歌研究につなげていくかが大切です。研究者のセンスが問われる部分ですね」
データサイエンスを用いて福田教授が分析し始めた初期の頃、これまで注目していなかった和歌のペアが出力されたことがあったという。深養父の和歌と兼輔の和歌だ。

「古今和歌集にある恋歌をもとにして、子どもを思う心情を詠んだ歌が、後撰和歌集のなかにありました。この和歌がいわゆる本歌取りの歌といってよいかどうかは研究者のなかでも意見が分かれるところでしょうが、少なくとも深養父が詠んだこの和歌を兼輔は知っていたはずです。この兼輔の歌は『源氏物語』のなかで、最も多く引き歌として用いられており、子を思う親心をいう「心の闇」ということばの由来にもなりました。実は、この兼輔、源氏物語の作者、紫式部の曽祖父です。そして深養父は、枕草子の作者、清少納言の曽祖父。一条朝に活躍したふたりの女房の因縁は、和歌を通して、曽祖父の時代にまで遡るとは、なんとも興味深いことですね」
「人」「心は」「にあらねども」「るかな」などは、和歌の骨組み部分。普通に眺めているだけでは、2首の和歌の類似性にはなかなか気づくことができないと福田教授は話す。しかし、兼輔と深養父の和歌のように、データサイエンスを用いることで、これまで見逃されてきたものが思いがけず浮上してくることがある。そんなときに、データサイエンスを駆使した文学研究の面白さを感じるという。

「文化情報学部には、文系と理系の学生が半分ずついます。そのため、理数系の科目は得意だけど、文系分野には苦手意識があったり、文学に興味がなかったりする学生も多くいます。しかし、『まずは文学作品ではなく、単なるデータだと思いなさい』と言って指導すると、しっかり論文やレポートを書いて卒業していくんですよ。むしろ理系の学生の方がセンスがあったりします。研究は根拠を提示していくことが大切なので、数値や客観的なデータを用いることが必要になります。とくに実証的な文学研究にデータサイエンスのスキルを生かせる場面は、もっとたくさんあるのではないかと思います」
データサイエンスを用いて、昔の人々の心を受け継いでいく
「高校生のみなさんにとって、大学で専門に勉強したい分野を決めるのは難しいかもしれません。実際、私が高校生の頃も専門に勉強したいことはとくにありませんでした。強いていえば、『源氏物語』や和歌に興味があるかなと思って、文学部への進学を選択したんですね。しばらくは何について研究しようかと迷っていたのですが、あるとき友人から情報科学の知見を教えてもらったことで視界が開けました。先ほどのデータマイニングの技術ですね。それを使ってみたら本当に楽しくて、データサイエンスを用いた文学研究にどんどんのめり込んでいきました」
同志社大学文化情報学部には、文学、哲学、音楽、映像学、考古学、言語学、社会学など、さまざまな学問分野の教員が所属している。そのため、まだ研究したい分野が決まっていなくても、入学してから専門に勉強したいことを探せるのが魅力だ。
「データサイエンスや情報技術のスキルを身につける授業とは別に、一般教養としてさまざまなテーマの授業を受けて、興味のあるコンテンツを探すことができます。私の日本古典文学の授業もそのなかのひとつです。和歌は、昔の人々が当時の風景の美しさや自分の気持ちを伝えようとして、継承されてきたもの。しかし、古文や変体仮名は多くの人が読めなくなっているのが実情です。そのため、情報科学の技術を用いて、かつての人々の英知を後世に伝えていければと考えています。情報科学の技術は今後さらに進化していくでしょうし、今回ご紹介したのとは別の技術も、今後、実証的な文学研究に導入されていくはずです。そのようなことに面白さを見出してくれる方がいれば、ぜひ一緒に古典和歌の世界で研究しましょう」
プロフィール
福田智子
同志社大学文化情報学部文化情報学科 教授
福岡女子大学文学部国文学科卒、九州大学大学院文学研究科博士後期課程満期退学。博士(文学)。専門は平安時代から鎌倉時代の和歌文学だが、友人でもある情報科学者との共同研究を契機に、文字列解析ツールや和歌のデータベース構築にも取り組む。
詳細はこちら
福田智子 教授
Text by 仲里陽平(minimal)/Illustration by カヤヒロヤ















