

【東京科学大学】ディープラーニングを用いた「自然言語処理」の現在地
東京科学大学 岡崎研究室

岡崎研究室
専門:自然言語処理/テキストマイニング/機械学習
AI・データサイエンス系大学・学部の研究室では、どのような研究が行われている? AI(人工知能)の研究分野のひとつに「自然言語処理」がある。話題のChatGPTも自然言語処理に特化した生成AIだと言われている。人間が日常的に使用する「ことば」をコンピュータで処理する研究とはどのようなものなのだろうか? 日本における自然言語処理研究のトップランナーである東京科学大学情報理工学院 岡崎直観教授を取材した。
人間の言葉を理解するコンピュータをつくる研究
AI(人工知能)に興味がある人なら、「自然言語処理」という研究分野について聞いたことがあるだろう。自然言語とは、日本語、英語など人間が日常的に使用する言葉のこと。自然言語処理とは、人間の言葉を理解できるコンピュータをつくる研究といってもいいだろう。話題のChatGPTも自然言語処理を得意とするAIアプリケーションのひとつだ。
東京科学大学情報理工学院の岡崎直観教授は、自然言語処理が専門で、現在の生成AIブームのずっと前からこの分野の研究に携わってきた。
「人間のように言葉を操るAIの実現を目指しています。そのために外国語の文章を翻訳する、相手と対話する、質問に答える、状況を説明する……といった知的なコミュニケーションをコンピュータ上で実現するための原理や方法を探究しています。言語学、統計学、機械学習などの知識をベースに、最近は深層学習(ディープラーニング)など最先端のアプローチも積極的に取り入れています」

自然言語処理といっても研究分野は上記のように多岐に渡る。岡崎研究室でも機械翻訳、質問応答のほか、自動要約、情報抽出、教育支援など、テーマは「言葉」を扱うさまざまな研究領域に広がっている。最近は、カスタマーセンターなども機械音声による自動応答が主流なのは、誰もが知る通り。このように身近な場所でも自然言語処理が使われている。
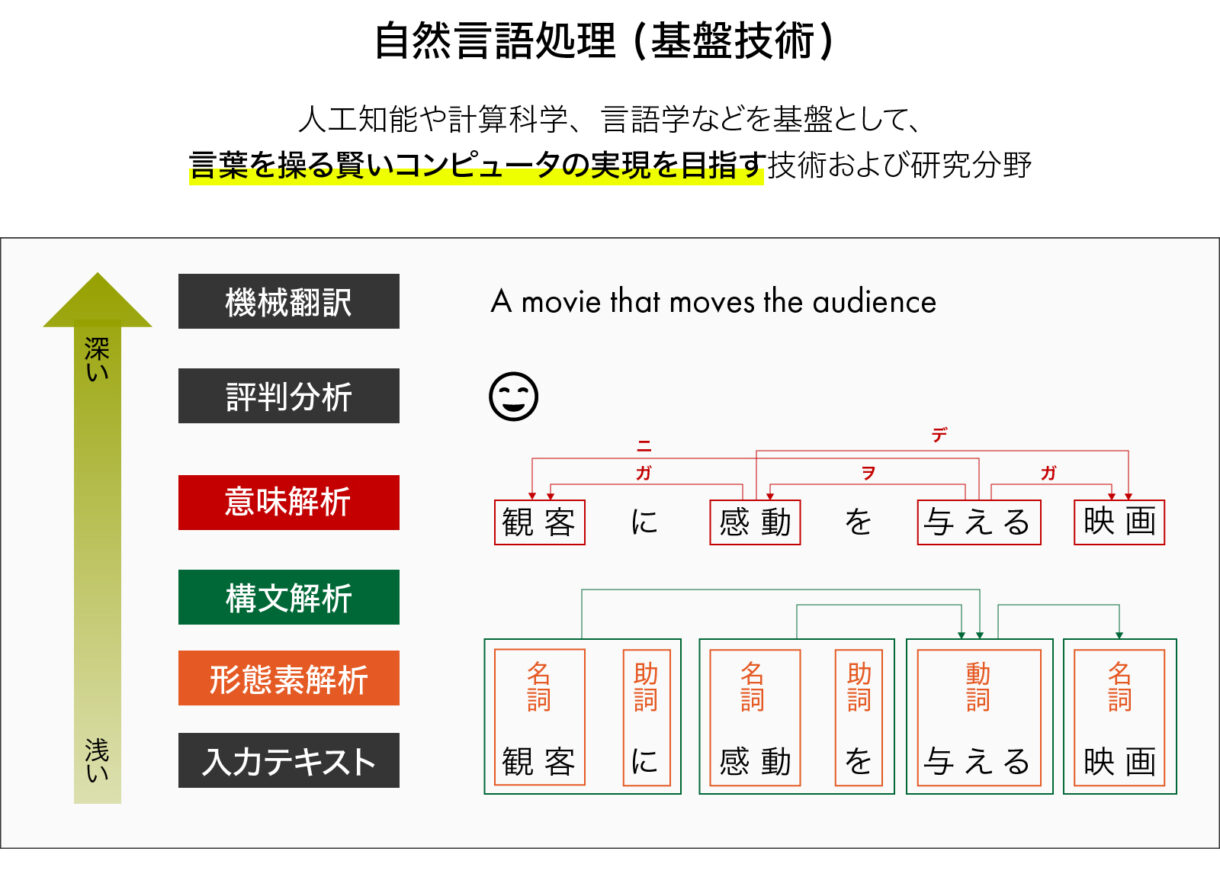
自然言語処理の基礎技術としては、文章を要素に分解し品詞などを判定する「形態素解析」、分解された要素間の係り受けなどの関係性を発見する「構文解析」、構文解析の結果から文章の意味を特定する「意味解析」、複数の文章の間のつながりを解析する「文脈解析」などがある。これを言語学や統計学、計算科学などを駆使して、進化させてきた。
伝統的な「統計的機械翻訳」とは?
自然言語処理の応用例の代表といえるのが、機械翻訳だ。これはコンピュータを利用して、ある言語で書かれた文章を別の言語に翻訳する変換を自動で行うものだ。
伝統的な「統計的機械翻訳」では、以下のような過程で処理が行われる。
【例】「私は東京に行きました」という文章を“I went to Tokyo”に翻訳する。
ここでは、「翻訳モデル」と「言語モデル」という2つの統計的モデルを用いる
- 1)翻訳モデル=単語の訳され方の傾向に関するモデル
- 例)「私は」=“I”/「東京」=“Tokyo”/「行った」=“went to”に訳される傾向にある
- 2)言語モデル=単語の並び方の傾向に関するモデル
- 例)“I”の後ろには“Tokyo”より“went to”の出現頻度が高い
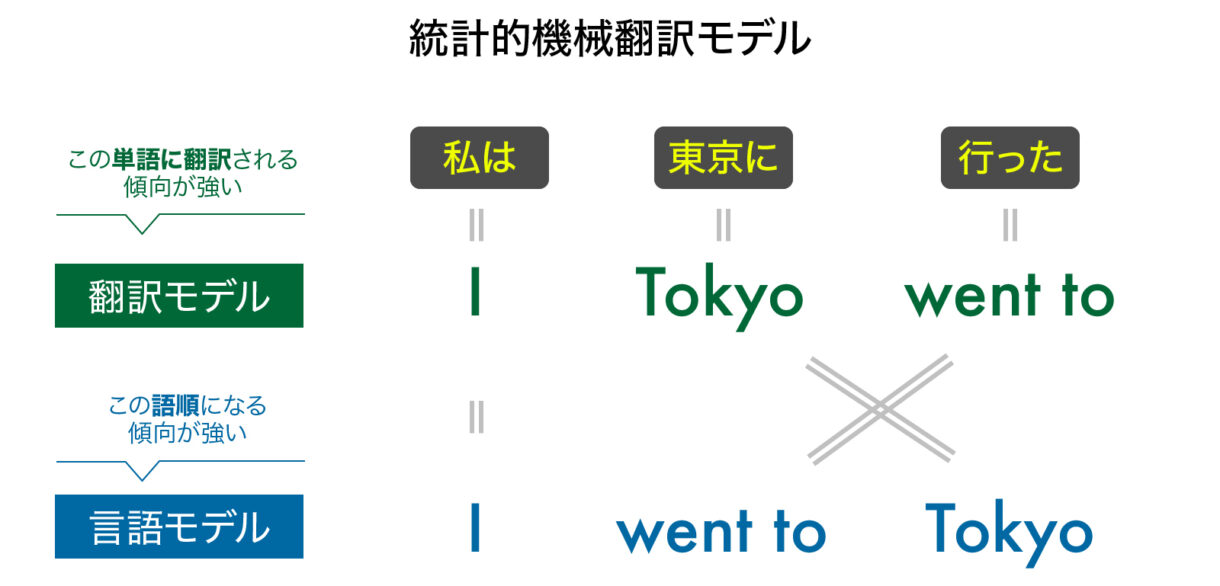
この2つのモデルを組み合わせることで、無数の候補の中から最もよい翻訳を選び出すことができる。つまり、統計的機械翻訳では、まず与えられた文を要素ごとに区切り、次に文の要素それぞれを翻訳する言語に置き換える。最後にそれを翻訳した言語において相応しい順番に並べるのだ。まさにデータサイエンスの手法である。
「最近登場したChatGPTの基盤にもなっているTransformerと呼ばれる深層学習モデルは、伝統的な自然言語処理の構文解析や意味解析をスルーして、機械翻訳や要約を実現することができます。もちろん文法を学習させる工程は経ていると思いますが、まったく新しいアプローチになります。ChatGPTに関しては、あと10年かかると思っていた技術が、ここ1〜2年で急に実現されたような感覚です。ただ、まだまだできていないことがたくさんあるのも事実です。よく言われる信頼性の問題などが代表例です。自然言語処理の技術は、深層学習の登場によって、さらに面白くなっていくでしょう」
ポイントは、言葉を「ベクトル」で表現すること
岡崎教授の研究室でも深層学習を用いた自然言語処理の研究を行っている。深層学習を改めて説明すると、人間の脳の神経細胞(ニューロン)の構造と働きを模した「ニューラルネットワーク」を多層に重ねて、複雑なパターン認識や予測を行う技術のことを指す。これを人間の言葉を操る技術にどう応用するのだろうか。
岡崎教授によれば、深層学習を用いた自然言語処理においてポイントとなるのは、言葉を「多次元ベクトル」で表現することだという。高校数学でも習うベクトルとは、「大きさと向きを両方持つ量」のこと。自然言語をなんらかの「数式」に変換する処理と理解しておけばいいだろう。ここで分析に用いるのが「分布仮説」。これは「単語の意味は、周辺に出現する単語の分布から推定される」という仮説を指す。
「英語の穴埋め問題を想像してください。これは、空欄になっている部分を前後の文章から予測して解く問題ですよね。これが解けるのは、単語の意味が周りの単語から推測できるからです。つまり、分布仮説に基づいて、単語を高次元のベクトルで表現すると各単語の周りに出現する別の単語の分布を統計的に分析することができます。その分布をもとに文脈を形成していくのです」
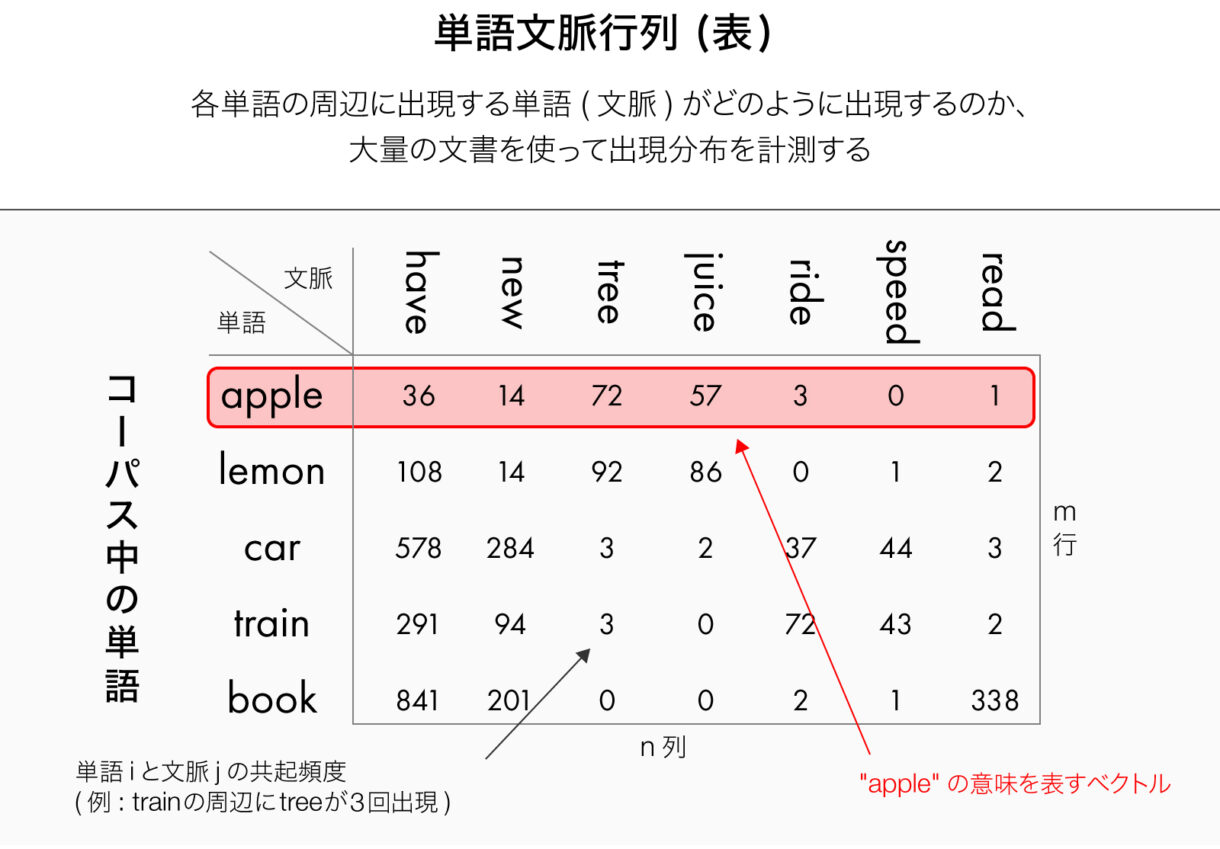
上の図は、岡崎教授が深層学習を用いた自然言語処理を説明する際のスライドの抜粋。マーキングされた部分が“apple”の意味を表すベクトルになる。これを分析すると周辺には、“juice”が57回、“tree”が72回出現していることがわかる。これら一連の分布から、この単語は“apple”であると推測できるという。難解ではあるが、自然言語処理の仕組みの一端がここから理解できるだろう。
大手通信社と共同で「新聞見出し」の自動生成技術を開発

こうした手法を用いて、岡崎研究室では、大手通信社と共同で、新聞記事から見出しを自動生成する技術を開発している。これは独自開発した自動翻訳モデルに大量の記事データを読み込ませて、訓練したもの。見出しの長さを制御したり、間違った情報が入り込まないように正確性を担保したりする機能もあるという。

深層学習モデルを用いた自然言語処理の応用範囲はさまざまな領域に及んでいる。深層学習によって、今や言葉だけでなく、画像や音楽もベクトル(数式)で表現できるようになった。そこで、出てきたのが、深層学習モデルを用いて、写真のキャプションを自動生成するような技術だ。
これは、ある画像の特徴を表すベクトルを「入力」として、キャプションとなる単語列を深層学習モデルで予測し、「出力」するもの。つまり、「画像」から「テキスト」を自動生成する技術になる。さらに最近は、生成AIの登場で、「テキスト」から「画像」や「音楽」を自動生成する技術も普及している。こうした汎用型のAIは、今後どのように進化していくのだろうか。岡崎教授の考えはこうだ。
「これからはマルチモーダルといって、テキストだけでなく、画像、音声などの複合的な情報を統合して理解するAIが出現するでしょう。わかりやすく言うとAIを搭載したロボットを部屋に置いておくと視覚、聴覚、触覚などのさまざまなセンサーを使って、空間を自動で認識し、自ら賢くなっていくようなイメージです。部屋のどこに何があるか、AIに教えてもらうような時代もすぐに来るのではないでしょうか」
大切なのは「AIに触れてみること」
最近では、昔では考えられないような高度な深層学習ツールが普及し、個人でダウンロードして、自宅のPCで動かせる時代になった。岡崎教授に言わせれば、これは「信じられないようなチャンス」だという。アイデアさえあれば、高校生でもこうした汎用型AIを使って、さまざまなイノベーションが起こせる。そのためには、まず「触れてみること」が何より大切だという。
「誰もがスマホでChatGPTを使える時代です。もはやAIを扱うハードルは高くありません。まずは、自分で調べて、機械学習や深層学習のツールを使ってみてください。その上で、こうしたAIの先端技術を使って、自分が何をしたいのか考えてみるのがいいでしょう。東京科学大学ではオープンキャンパスや“工大祭”(大学祭)などで、AIやロボットに触れることができます。興味ある人は、ぜひ訪れてみてください」
研究室の詳細
東京科学大学 情報理工学院 岡崎研究室
「自然言語処理」の研究を中心に、AI(人工知能)の実現を目指している。研究テーマは、機械翻訳、質問応答、自動要約、情報抽出、教育支援など多岐にわたる。言語学、統計学、機械学習などの基礎知識を踏まえながら、深層学習などの最先端のアプローチも積極的に行う。ビッグデータ解析による社会観測など、研究成果の実社会での応用も展開している。
詳細はこちら
東京科学大学情報理工学院岡崎研究室
Text by 丸茂健一(minimal)/Illustration by 竹田匡志
UNIVERSITY INFO

全学教育組織「データサイエンス・AI全学教育機構」を設置
2024年10月に誕生した東京科学大学は、世界に開かれた「Science Tokyo」としてグローバルに進展していく。伝統ある東京医科歯科大学・東京工業大学それぞれの専門分野のみならず、人文科学・社会科学的な視点をも含めた「科学」の発展を担い、社会とともに活力ある未来を築くことを目指す。全学教育組織「データサイエンス・AI全学教育機構」を設置し、社会的課題解決やDS・AI研究開発を強力に推進することのできるDX人材を育成する。
カテゴリ
国立大学
学院
■理学院 ■工学院 ■物質理工学院
■情報理工学院 ■生命理工学院 ■環境・社会理工学院
■医学部 ■歯学部 ■医歯学総合研究科 ■保健衛生学研究科
所在地・アクセス
- 大岡山キャンパス
- 〒152-8550 東京都目黒区大岡山2-12-1
東急大井町線・目黒線「大岡山」駅下車、徒歩1分 - すずかけ台キャンパス
- 〒226-8501 神奈川県横浜市緑区長津田町4259
東急田園都市線「すずかけ台」駅下車、徒歩5分 - 田町キャンパス
- 〒108-0023 東京都港区芝浦3-3-6
JR山手線・京浜東北線「田町」駅下車、徒歩2分 - 湯島キャンパス
- 〒113-8510 東京都文京区湯島1-5-45
JR・東京メトロ丸ノ内線「御茶ノ水」駅、
東京メトロ千代田線「新御茶ノ水」駅下車、徒歩3分 - 駿河台キャンパス
- 〒101-0062 東京都千代田区神田駿河台2-3-10
JR・東京メトロ丸ノ内線「御茶ノ水」駅、
東京メトロ千代田線「新御茶ノ水」駅下車、徒歩5分 - 国府台キャンパス
- 〒272-0827 千葉県市川市国府台2-8-30
京成線「国府台」駅下車、徒歩15分
問い合わせ先
東京科学大学 アドミッションセンター
TEL:03-5734-2067
Mail:admi.cen.se@adm.isct.ac.jp



この記事に紐づくタグ
この記事をシェア
同じ大学のその他の記事
こちらの記事もチェック
-

RESERACH
【東京大学松尾・岩澤研究室】ディープラーニングで「世界」を獲得する
鈴木 雅大 特任助教
東京大学
松尾研究室 -
RESERACH
稲見 昌彦 教授
東京大学先端科学技術研究センター身体情報学分野
稲見・門内研究室 -
RESERACH
【日本大学文理学部】「AI×心」の最先端研究でドラえもんを本気でつくる!
大澤 正彦 准教授
日本大学
文理学部 情報科学科大澤研究室 -
RESERACH
【慶應義塾大学】人とAIとの共同作業で手塚治虫の傑作マンガを更新する!
栗原 聡 教授
慶應義塾大学理工学部
栗原研究室 -
RESERACH
【東京農工大学】ディープラーニングを用いて脳波から自動で音声を合成する
田中 聡久 教授
東京農工大学
田中聡久研究室 -
RESERACH
【東京農工大学】情報技術を用いて「ウェルビーイング」を実現する!
藤波 香織 教授
東京農工大学
藤波研究室






この領域を学べる大学・学部・学科
-

【東洋大学 情報連携学部】「文・芸・理」の連携によってDXを推進する
東洋大学情報連携学部(INIAD)
-

【一橋大学】社会科学+データサイエンスで現代社会の課題を解決する
一橋大学
ソーシャル・データサイエンス学部
-

【京都産業大学】データサイエンスと組み合わせて10コースから専門を選べる
京都産業大学
情報理工学部
-
九州情報大学
経営情報学部情報ネットワーク学科




この研究に関連する職業



この記事を読んだ人におすすめの記事
-

FUTURE
【東洋大学INIAD】「チーム実習」座談会 チームで社会課題と向き合った成果を学会でポスター発表!
川浦 弘暉 さん、荒巻 杏実 さん、宮原 咲弥 さん、原 良 さん
東洋大学
情報連携学部(INIAD) -
FUTURE
【東京大学医学部】医療とテクノロジーを融合させた未来を模索中!
松村 大央 さん
東京大学医学部
医学科 6年 -

REPORT
2027年度版:情報系/データサイエンス系学部の総合型選抜まとめ【東日本編】
データサイエンス百景編集部
-
REPORT
2027年度版:情報系/データサイエンス系学部の総合型選抜まとめ【西日本編】
データサイエンス百景編集部
-
RESERACH
【明星大学】なぜ言葉は通じるのか——計算言語学で「いい文章」の仕組みを解明する
横野 光 准教授
明星大学 情報学部
計算言語学研究室 -
UNIVERSITY
【青山学院大学】「統計」を冠した5学部連係の「学環」で学ぶデータサイエンスとは?
青山学院大学統計データサイエンス学環
(2027年4月開設予定)






みんなが見ている情報をチェック
人気記事
-
1

-
2

-
3
-
4
FUTURE
【東洋大学INIAD】「チーム実習」座談会 チームで社会課題と向き合った成果を学会でポスター発表!
川浦 弘暉 さん、荒巻 杏実 さん、宮原 咲弥 さん、原 良 さん
東洋大学
情報連携学部(INIAD) -
5




人気キーワード
-
1
データサイエンス -
2
AI(人工知能) -
3
環境保全/エコロジー -
4
ChatGPT -
5
機械学習
注目のキーワード
-
1
AI(人工知能) -
2
生成AI -
3
ディープラーニング(深層学習) -
4
ブレインマシンインターフェース -
5
メタバース
